Reasoning Like Program Executors
基于自然语言的推理一直是一个比较重要的问题,目前的大规模预训练模型普遍缺乏真正的推理能力,因为它们在训练时候的任务,无论是像BERT的掩码语言模型,还是GPT的自回归语言模型,建模的仍然是token与token之间共现的概率分布,而缺乏对整体语义的把控,虽然NSP任务也想建模整体语义,但Anyway,现在做不好,也许基于统计的概率分布建模做到头也没法获得“推理能力”。
这篇文章提出了一种新的预训练任务,叫作 reasoning-enhancement pre-training,证明了除概率建模以外,推理能力建模也是有作用的,同时模型的推理能力具有泛化性。
Reasoning
那么,什么是“推理能力”呢?举个例子,“小明家里有5块巧克力,小明的妈妈下班回来的时候发现只剩下3块了,由此可以推出小明吃了2块巧克力”,在这段的自然语言描述中,我们可以得到原本的巧克力数量为5,剩下的巧克力数量为3,推理出被小明吃掉的巧克力数量5-3=2,进一步简化成一个可执行的符号系统,就是输入x=5, y=3, z=x-y,求输出结果z。
通过将信息从承载它的表面模态和符号抽象中分离出来,人类能够统一信息输入的格式,并将数字推理能力浓缩成一个可执行的符号系统。因此,如果一个模型能够通过模仿程序执行器来掌握这些推理技能,那么将这些推理技能迁移到其他模态上就是有可能的了。
既然基于自然语言的推理能力不好,那么很容易想到的是把该问题拆解成更小的问题解决。作者将推理任务分为4种:数值推理,逻辑推理,多跳推理以及混杂文本(其实我觉得这里说成结构化文本更好,因为主要就是对应Table QA)推理,其实还有一个常识推理,但leave for future,一些例子:
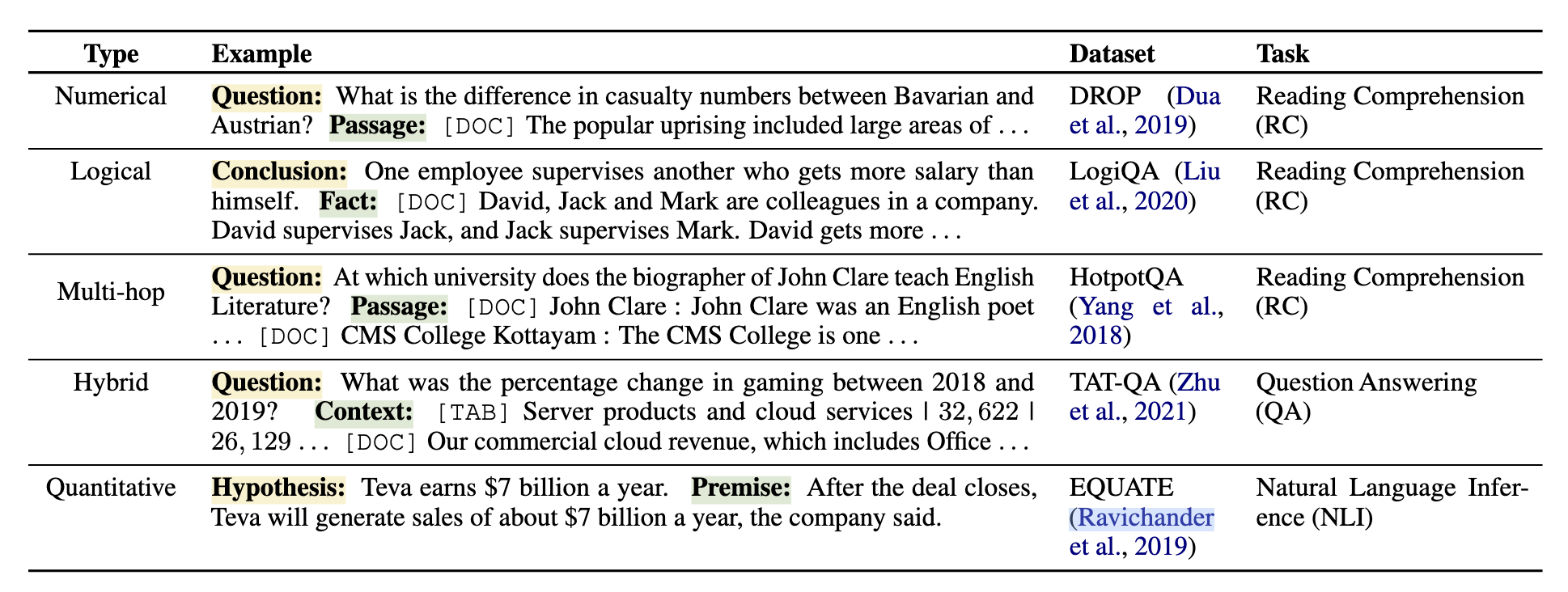
推理方面也有不少工作,具体而言,分成两类:
- 设计专有模块处理,比如数值推断中,采用特有的计数模块。一般来说,能提出来,效果肯定不错,但专有模型的泛化性肯定是个问题,我们既然做预训练模型,就是希望能有一个通用的解决方案,不需要繁杂的下游操作。格局—>打开
- 设计对应的预训练方案,需要大量的包含推理知识的自然语言数据,已有的方法也是这么干的,但是推理数据的收集或生成真的很困难,也很麻烦。然而,试想一下,我们人具有数字推理能力也不是从语言中学习到的,我们是通过学数学学到的,但我们有很强的泛化能力:),能把数学课上学到的加减乘除泛化到日常用语。问题自然来了,如果我们给预训练模型上数学课,或者逻辑推理课,它能不能泛化?这篇文章就是在思考并且验证这个事情,它究竟能不能更像人,笔者认为其思考的深度和格局,已经远超已有方案。
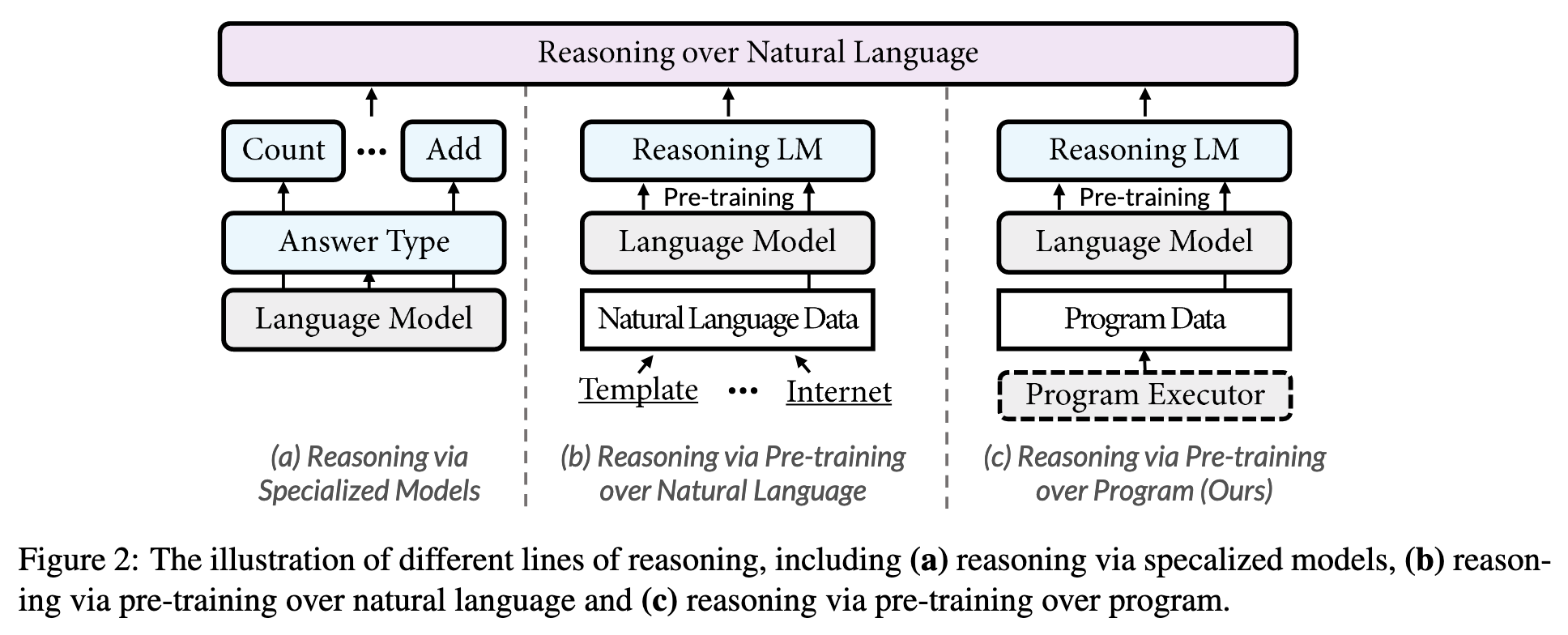
POET
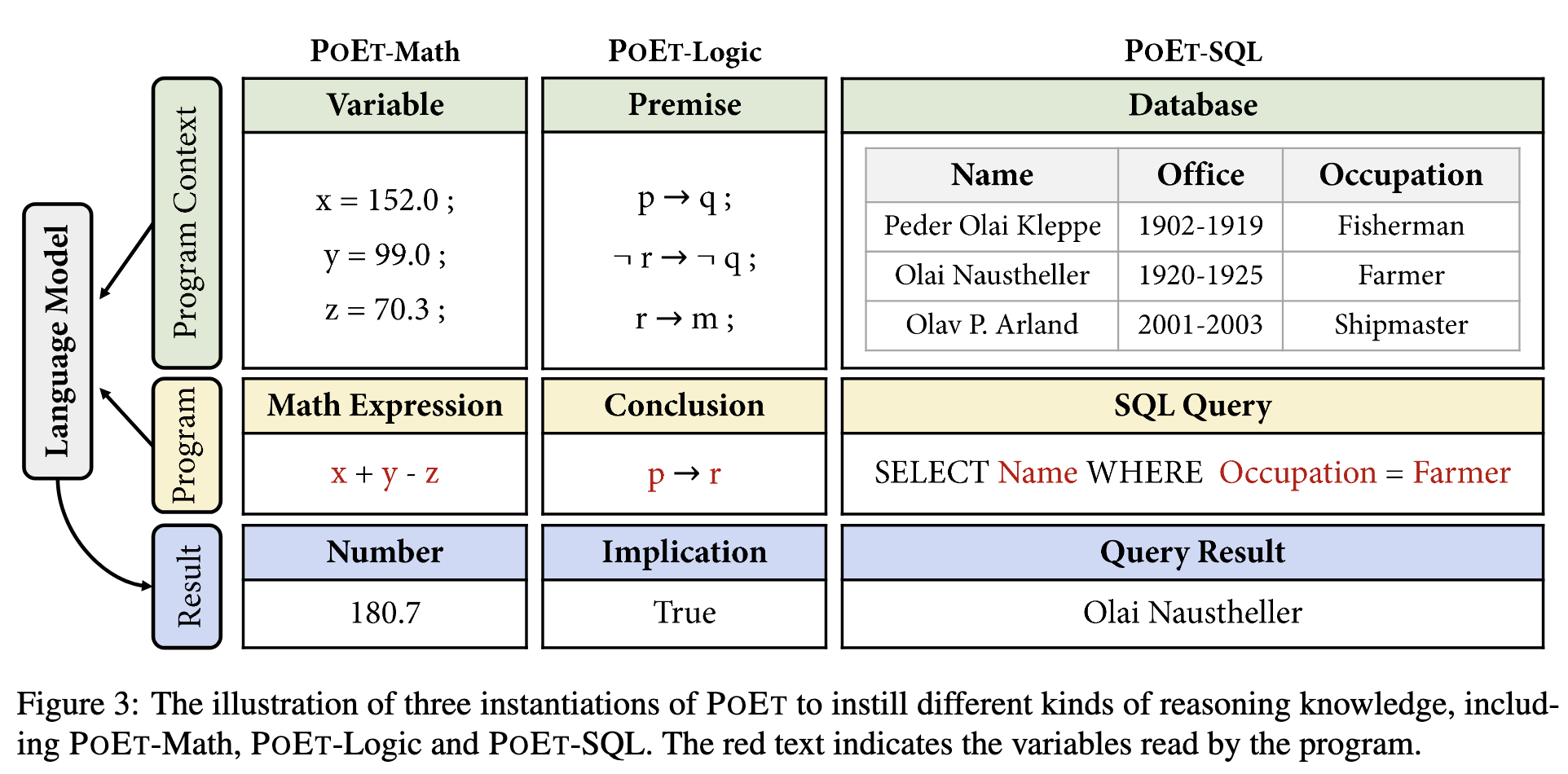
作者提出的模型叫作 POET (Program Executor),由四个基本组件构成,分别是 Program,Program Context,Program Executor 和 Execution Result,下面分别简单介绍。
Program
程序其实就是一段能被机器理解和执行的符号,比如我们代码print(string_1),比如一个数学公式x+y-z,一般来说比自然语言更为正式,遵守固定的语法。
Program Context
程序上下文,包括程序所执行的环境,程序中变量的值,比如上面的例子中,string_1 = "Hello World",x=5, y=3, z=1。program 与 program context 的关系很像阅读理解中 question 与 passage 之间的关系。
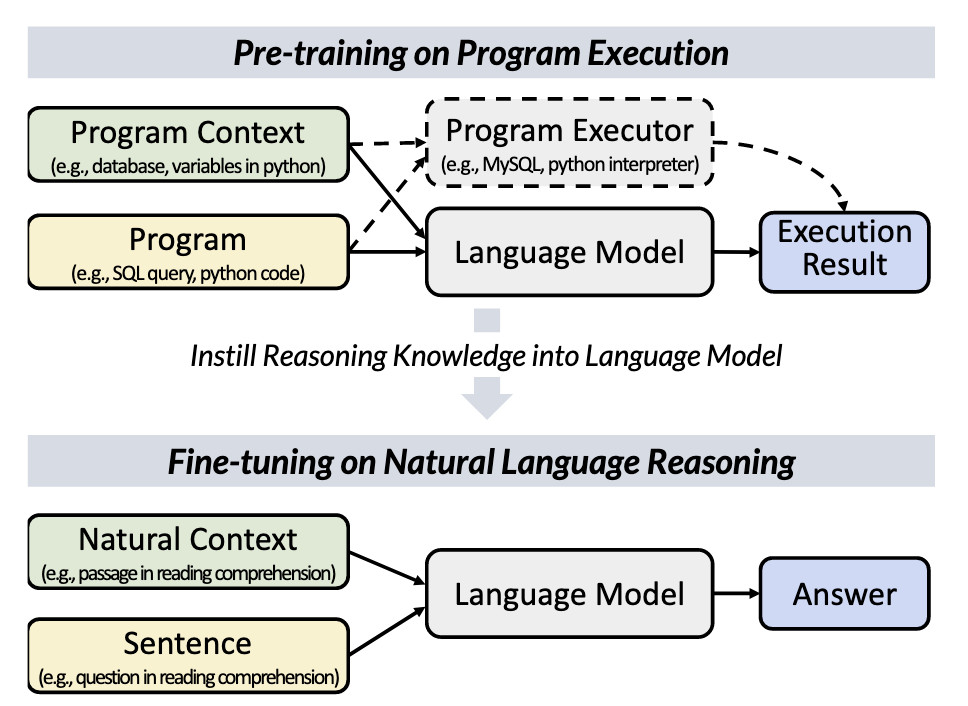
Program Executor
程序执行器就是一个黑盒子,只要给定 program 和 program context,它就能输出一个结果,比如它可以是一个计算器,你给任何公式和变量,它能输出一个结果,我们并不用知道它内部的电路实现,它也可以是 python 解释器,只要你写的代码符合 python 的规范,它就能输出正确的结果,我们并不用关心它是怎么实现的。程序执行器扮演的就是 Language Model 老师的角色,只要程序和程序上下文确定了,它输出的结果总是确定的,因此我们希望模型能够学到程序执行器中蕴含的推理能力。
Execution Result
执行结果就是程序执行器的输出,它是反映程序执行器内部逻辑的可观察数据,是程序执行器提供的监督信号,就像NLP中下游任务的标签,指导模型的学习。
实例化 POET
针对四种推理任务,论文设计了三种课程:数学课,逻辑课以及数据库课 (POET-Math, POET-Logic, POET-SQL) 。这里采用数据库课程的原因是它太全面了,覆盖了数值、条件、嵌套等数值推理和多跳推理任务。
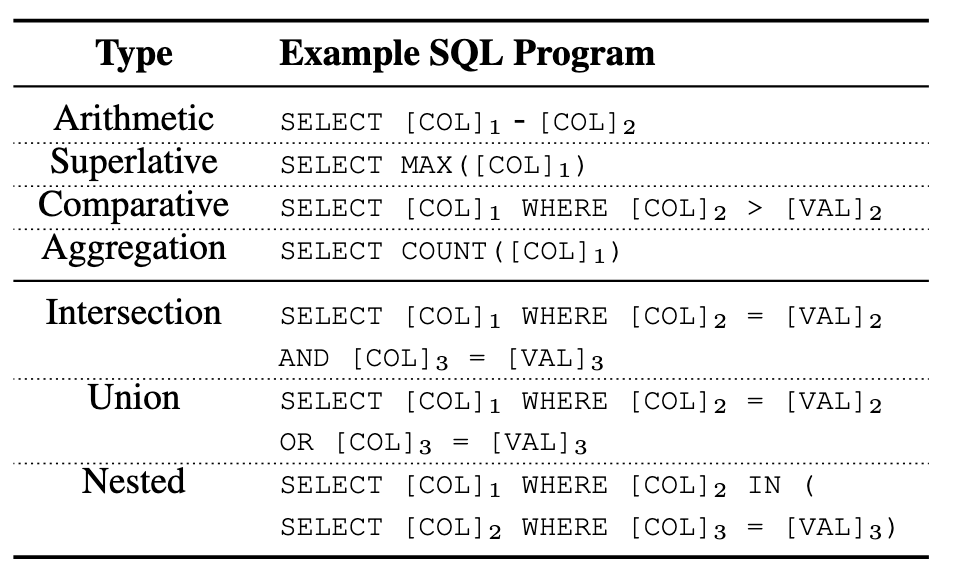
好的,那就开始给预训练模型上课了。拼接程序与程序上下文,作为模型输入,训练模型预测程序执行器输出的结果。数据就是用代码随机生成的,相比于自然语言数据,这种数据的生成更简单,可以轻易造出上百万的数据。
实验结果
实验结果还是很不错的
数学课和逻辑课,效果很显著。
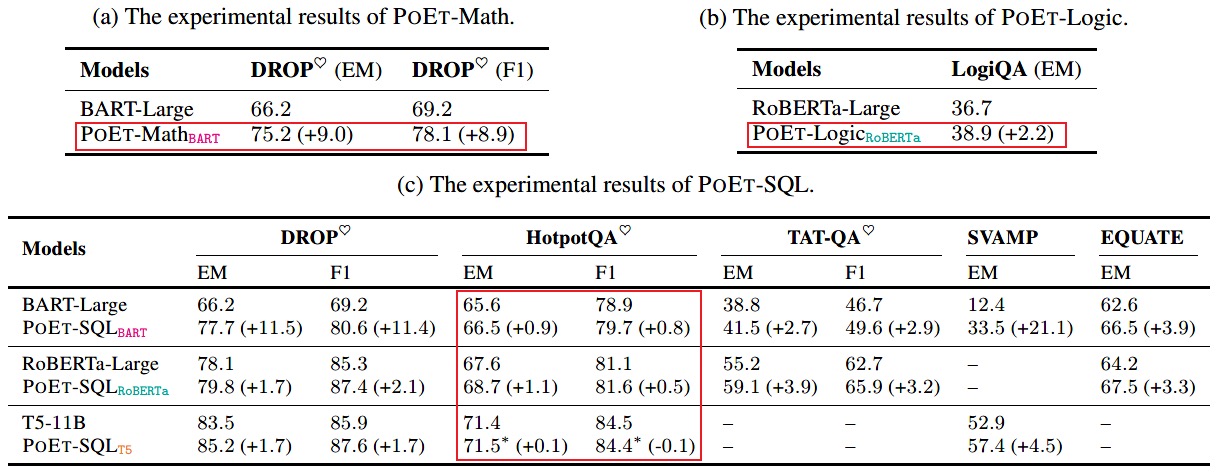
BART在文本理解类任务上显著差于RoBERTa,其原因来自于RoBERTa更优秀的双向注意力机制,即使BART含有双向注意力的Encoder,但是其预训练任务是更侧重于Decoder的。有趣的是在BART原文中在自然语言理解类任务上其效果与RoBERTa差不多,但是Anyway,其Loss与Decoder更相关,Decoder存储了部分语义信息,因此有理由相信其Encoder的双向注意力机制差于RoBERTa。
在多跳推理上的提升不是很明显,原因可能是:文本的多跳推理要求对段落语义有较强的理解,而SQL不需要对同行列信息有比较深入的了解,只要知道其值是什么就OK了,似乎还可以把这里设计的更复杂一点。
- 还值得注意的一点是T5-11B,也就是100倍大的BERT,效果显著的比参数小的模型要好。预训练任务都差不多,但大模型就是更强一点,多出来的参数到底起到了什么作用?
文章在实验结果章节有这么一段话:Since POET pre-training is carried purely on program context, whereas all downstream tasks are on natural context, our hypothesis that reasoning capability is transferable from program executors to NL scenarios gets verified. 简单总结一下,实验部分证明了模型从符号化,抽象化的数据中学习到的推理能力是可以迁移的,模型并非只是简单的学到了概率估计,而是真正的学习到了解决相关问题的推理能力,且具有一定的泛化性,Amazing!